
郑州慧策企业管理咨询有限责任公司
主营:数据分析师(CPDA)培训,企业数据分析内训
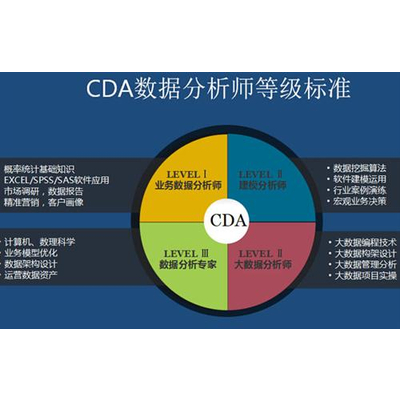
数据分析师,数据分析师*,CPDA河南授权中心(多图)
面议
中国
来电请说明在第一枪看到,谢谢!
产品属性
后来随着开源运动的迅速发展,一大批此类新技术开始共享到更广的范围。 然后,一些互联网大公司的工程师离职去创办自己的大数据初创企业。其他的一些 “数字原生” 公司,包括崭露头角的独角兽公司,也开始面临着互联网大公司的类似需求,由于它们自身也没有传统的基础设施,所以自然就成为了那些大数据技术的早期采用者。


专门的大数据应用几乎在任何一个垂直行业都有出现,从医疗保健(尤其是*组学和*研究)到****、时尚乃至于*(如 Mark43)。
有两个趋势值得强调一下。首先 ,这些应用很多都是 “大数据原生” 的,本身都是依托在新的大数据技术基础上开发的,代表了一种客户无须部署底层大数据技术即可利用大数据的有趣方式—因为那些底层技术已经是打包的,至少对于特定功能来说是这样的。
自我们发布上一版大数据版图以来,这个利用了内存处理的开源框架就开始引发众多讨论。自那以后,Spark 受到了从 IBM 到 Cloudera 的各式玩家的拥护,让它获得了可观的信任度。Spark 的出现是很有意义的,因为它解决了一些导致 Hadoop 采用放缓的关键问题:Spark 速度变快了很多(基准测试表明 Spark 比 Hadoop 的 MapReduce 快 10 到 100 倍),更容易编程,并且跟机器学习能够很好地搭配。
内容声明:第一枪网为第三方互联网信息服务提供者,第一枪(含网站、微信、百家号等)所展示的产品/服务的标题、价格、详情等信息内容系由卖家发布,其真实性、准确性和合法性均由卖家负责,第一枪网概不负责,亦不负任何法律责任。第一枪网提醒您选择产品/服务前注意谨慎核实,如您对产品/服务的标题、价格、详情等任何信息有任何疑问的,请与卖家沟通确认;如您发现有任何违法/侵权信息,请立即向第一枪网举报并提供有效线索至b2b@dyq.cn