
郑州慧策企业管理咨询有限责任公司
主营:数据分析师(CPDA)培训,企业数据分析内训
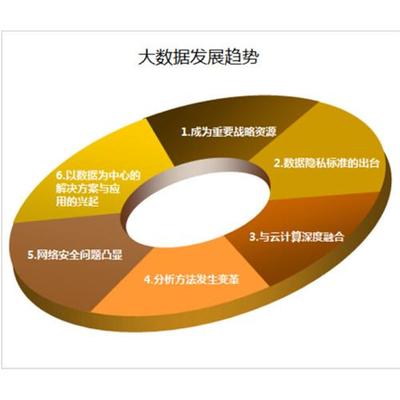
数据分析师,CPDA河南授权中心,数据分析师报考条件
面议
中国
来电请说明在第一枪看到,谢谢!
产品属性
大数据基础设施:仍有大量*,关于 MapReduce 和 BigTable 的*(Cutting 和 MikeCafarella 因为这个而做出了 Hadoop)的诞生问世已有 10年 了,在这段时间里,大数据的基础设施层已经逐渐成熟,一些关键问题也得到了解决。
但是,基础设施领域的*仍然富有活力,这很大程度上是得益于可观的开源活动规模。无疑是 Apache Spark 之年 。

你得****数据、存储数据、清洗数据、查询数据、分析数据并对数据进行可视化。这些工作一部分可以由产品来完成,而有的则需要人来做。一切都需要无缝集成起来。后,要想让所有这一切发挥作用,整个公司从上到下都需要树立以数据驱动的文化,这样大数据才不仅仅是个 “东西”,而且就是那个(关键的)“东西”。

许多情况下,他们正处在这样一个重要的拐点上,即经过大数据基础设施的数年建设后,能够展示的成果还不多,至少在公司内部的商业用户看来是这样的。但是大量吃力不讨好的工作已经做完了,现在开始进入到有影响力的应用部署阶段了。只是从目前来看,这种建构在核心架构之上的应用数量还不成比例。

内容声明:第一枪网为第三方互联网信息服务提供者,第一枪(含网站、微信、百家号等)所展示的产品/服务的标题、价格、详情等信息内容系由卖家发布,其真实性、准确性和合法性均由卖家负责,第一枪网概不负责,亦不负任何法律责任。第一枪网提醒您选择产品/服务前注意谨慎核实,如您对产品/服务的标题、价格、详情等任何信息有任何疑问的,请与卖家沟通确认;如您发现有任何违法/侵权信息,请立即向第一枪网举报并提供有效线索至b2b@dyq.cn